

Tips Are Not Enough for a Killer SharePoint Search System
September 11, 2012
We read “5 Tips for Turning a SharePoint 2010 Search Center into a Find Center.” The points are useful and include such suggestions as appointing a search administrator, have a SharePoint Search plan, and monitor the search system.
We found this passage interesting:
The default Search Center above might be enough for some sites (hey, the minimalist approach works for Google), but with some work, you can turn this into a Search Center that is useful enough for users to set it as their home page. You can get a lot of good ideas from the white paper How Microsoft IT Deployed FAST Search Server 2010 for SharePoint, especially the Enterprise search center article. This screenshot from the white paper provides an example of what you can do with your Search Center. FAST Search Server will give you a richer experience on the search results page, but the items you see on this Search Center are achievable with SharePoint 2010—or even SharePoint 2007. To create a Search Center that is the go-to place for your users, you can add helpful information such as links to event calendars, corporate news, campus maps, benefits, expense reporting, and research portals.
In our experience, SharePoint Search can deliver high-value services to users throughout an organization. SharePoint, particularly with its distributed and cloud capabilities, can now provide exceptional information access across a wide range of on premises and remote worker use cases.
However, only a handful of consulting services firm have the technical expertise and hands-on experience necessary to deploy a SharePoint solution in a matter of days. Search Technologies has implemented hundreds of SharePoint Search solutions, and the firm’s technical staff knows how to move through a project from its inception to its customization and optimization in an efficient manner.
If you want to move SharePoint to the next level, consider Search Technologies.
Iain Fletcher, September 11, 2012
Sponsored by Augmentext
xx
Information about Search for SharePoint 2013
September 6, 2012
We have been tracking useful sources of information about search for SharePoint 2013. You will find the three minute video prepared by Search Technologies an excellent place to begin. Search Technologies points out that the Fast search technology, acquired by Microsoft in 2008, and it is at the heart of SharePoint 2013. Technologies and ideas from Bing and elsewhere have been added to the mix to provide a comprehensive set of enterprise search capabilities, with plenty of room for customization. Search for SharePoint 2013 includes a rules-based query parsing framework. Search Technologies indicates that pricing has not yet been formally announced, but it is generally assumed that this search functionality will be a standard part of SharePoint 2013. See http://www.searchtechnologies.com/sharepoint-15-search-overview.html.
Microsoft has done a great job of providing information about SharePoint 2013 search. I wanted to make sure you knew that a series of articles is pulling together much of the Microsoft information and adding some insights that could be difficult to locate.
We can point out another useful source of information in this Microsoft document.
The author is Nicki Borell. The first three parts of his coverage of SharePoint 2013 discuss:
- Office 365
- What Happens with Fast in SharePoint 2013
- Search Dictionaries, Query Builder, Query Client Type.
Two more articles will appear in the near future, and these will cover administrative changes and user interface modifications.
Our engineers at Search Technologies track SharePoint 2013 on an hourly basis. We found that the discussion of dictionaries, query builder, and query client type were useful for two reasons:
- The articles include screenshots which make it easy to get oriented in a graphical or PowerShell environment
- There is sufficient descriptive narrative to make clear the specific feature; however, for those working with certain large SharePoint environments, additional explanation might prove useful to some system administrators.
Search Technologies has the deep experience required to handle basic and advanced SharePoint configuration, customization, and integration for any size SharePoint deployment. For more information, visit http://www.searchtechnologies.com/.
Iain Fletcher, September 6, 2012
Sponsored by Augmentext
Kona Data Search Bets on Salesforce as Salesforce Swims Against the Current
August 27, 2012
One-size-fits-all search has become a tough sale. Presumably clever enterprise search vendors have embraced wordsmithing in order to boost sales. Examples range from converting a deduplicating technology into big data, shifting an entity extraction program to business analytics, and presenting XML as a “new” content manipulation tool which slices, dices, and chops with ease.
I learned via a random LinkedIn message that a copy called Kona Data Search. I pinged the company, was promised information, and even followed up (a rare action for the addled goose). After some dithering, I checked out the company’s Web site (which created some choking and stumbling for my so-so Chrome browser) and learned:
Kona Search [for Salesforce] is a relevancy-based text search application for Salesforce, with a Search Results page and a pop-up sidebar, or “Search Gadget,” for persistent display. Relevancy is a way of sorting search results based on how well they match the terms in a user’s query. You may be familiar with relevancy from public web search applications like Google search. KonaSearch applies the same principals to Salesforce objects. Also like the web search applications, KonaSearch highlights the words that match in the results so you can see why an object was included. The current release can search text, dates, and numbers for the main Sales Cloud objects. Immediately following this release will be more Salesforce products, Chatter®, and Microsoft Outlook.
Searching for information on Salesforce is okay. There are problems when one has quite a few employees using Salesforce and a super user needs to pinpoint a specific email or contact interaction chain for something like eDiscovery or checking up on a sales professional who has just resigned.
Kona asserts that it delivers such functionality as:
- Auto suggestion
- Field specific search
- Date and number search
- Entity extraction
- Facets
- Nested Boolean
- Phrase detection
- Spelling correction
- Stemming
- Synonym expansion
- Term biasing (weighting)
- Wildcards
The service costs about $240 per user per year.
In short, Kona includes the basics of what might be called traditional enterprise search. Google’s original search appliance intentionally trimmed such functions from its user interface. The assumption was that enterprise users don’t know how to formulate complex queries and are more interested in slamming in a word or two and getting relevant results. We know that neither traditional enterprise search nor the Google approach has hit home runs over the last few years.
What makes Kona interesting is that it is approaching the market with what appears to be an initial focus on Salesforce. (Versions of Kona for other systems is promised, however.) Now Salesforce is an interesting company, but I heard a rumor that Google considered purchased Salesforce seven years ago. But Google passed. Now Salesforce has to fight the likes of Oracle and smaller companies’ iPad apps to stay in the game. Salesforce has the same cost control problem that is gobbling Amazon’s margins.
According to “Salesforce Losses Swell, Despite Rise in Sales,” high flying Salesforce may have sucked some errant geese into its jet engines. The Register said:
Software-as-a-Service pin-up Salesforce.com reported growing losses despite increased sales. The hosted CRM provider reported a loss of $9.82m on a 34 per cent increase in net sales to $73.6m for the three-month period to 31 July.
Then added, “The company’s costs are increasing as it adds more staff to sell to the enterprise, against rivals such as Oracle and SAP.”
Here in Harrod’s Creek, the river dogs say, “Rising water lifts them boats.” What happens when the water level falls? Will Kona be able to float the Salesforce boat or will Salesforce get stuck in the mud and drag down Kona? We are monitoring the revenue flow gauge.
Stephen E Arnold, August 27, 2012
Sponsored by Augmentext
Enhanced Document Filters from dtSearch
August 21, 2012
We learn that dtSearch is beta testing its product line’s version 7.70 from Technology Magazine in “Beta Enhances dtSearch Document Filters to Display Highlighted.” The press release tells us:
“dtSearch Corp., a leading supplier of enterprise and developer text retrieval along with document filters, announces beta testing of Version 7.70 of the dtSearch product line. The new version adds multiple improvements to the document filters spanning the dtSearch product line. For customers in need of data parsing, conversion and extraction only, the dtSearch Engine APIs (native 64-bit/32-bit, Win/Linux C++, Java and .NET through 4.x) also make the document filters available for separate OEM licensing.”
Besides the dtSearch Engine, available for Windows and .NET or for Linux, the new release also applies to dtSearch Web with Spider, dtSearch Network with Spider, dtSearch Publish, and dtSearch Desktop with Spider.
Users of the new version will find that it supports a wide array of data types, and that image support has been added to Word, PowerPoint, Excel, Access, RTF, and email files. Enhancements have also been made to the multi-level nested configurations, including a new “object extraction” API. The write up also emphasizes the following features: built-in spider functionality; a terabyte indexer; assorted search options; and international language support. See the press release for more details.
Incorporated in Virginia in 1991, dtSearch began its text retrieval R&D back in 1988. Business and government organizations in over 70 countries rely on its wide product line to manage a myriad of data related tasks.
Cynthia Murrell, August 21, 2012
Sponsored by ArnoldIT.com, developer of Augmentext
SharePoint Server 2013 Preview
August 13, 2012
Microsoft posted two documents which we believe merit any SharePoint licensee’s attention. The principal features of the latest SharePoint appear on the Microsoft SharePoint site.
Search will be particularly important because SharePoint 2013 will make it easier to incorporate social content and support mobile access. The new SharePoint will be available later this year or early in 2013. Getting a head start is important if you plan to upgrade.
The SharePoint Server 2013’s enterprise search model provides information we found quite useful. The diagram’s PDF is 560 Kb and available from the Microsoft download center. The PDF covers:
- Search Components, including the application components and the search databases
- Example topologies. The illustrated use case is a medium-sized search farm with 40 million items or content objects in the system
- Scaling out. The diagram includes a proposal model for a search farm which handles 100 million item or content objects.
Of particular value are the details for the hardware required to support the 100 million item farm. A series of tables covers the scaling considerations, detail about the application servers recommended, and a table layout the hardware requirements necessary to handle upticks in the volume of content to be processed.
In the general guidance section, Microsoft points out that one additional crawl database is needed per additional 20 million items. One link database is recommend per additional 60 million items. The schematic’s detail recommends that the system include redundancy.
Bottom line, there is no mistaking the Fast-like functionality described here. Search Technologies has delivered more than 30,000 consultant-days of search implementation services to Fast and SharePoint users since 2005. We believe that this new search functionality will be widely adopted over the next few years, and we look forward to helping our customers to implement it.
Iain Fletcher, August 13, 2012
Sponsored by Augmentext
Open Source Solutions Continue to Gain Popularity
August 13, 2012
The H Open recently reported on some new developments for the open source search, discovery and analytics company Lucid Imagination in the article, “Lucid Imagination Becomes LucidWorks.”
According to the article, after continuously having customers confuse the name of the company with its flagship product, Lucid Imagination decided to go along with the customers perceptions and change its name to LucidWorks as means of avoiding further complicating branding efforts.
In addition its two product lines: LucidWorks Search and LucidWorks Big Data, both of which draw from open source products, the company has some additional plans on the horizon:
“LucidWorks has also announced that, in September, it will be setting up a community site called SearchHub.org, which will be oriented at developers. It is planned that this will include a blog from Lucene/Solr committers; of the 35 committers on the project, nine work for LucidWorks. Other planned features include video tutorials, podcasts, a community forum, up-to-date information on Lucene/Solr, and a calendar of enterprise search related hackathons and meetups.”
LucidWorks is an example of a company that has created an enterprise-grade embedded search development solution built on the power of the Apache Lucene/Solr open source search project. As technology continues to advance, companies that utilize open source technology are going to have an edge over their competition.
Jasmine Ashton, August 13, 2012
Sponsored by ArnoldIT.com, developer of Augmentext
Neofonie Technology Underpins Labdoo
August 10, 2012
Neofonie GmbH, based in Berlin, Germany, is a long-term player in search; the company has been in the market since 1998 and created the early German search engine fireball.de. Their technology is now being used at Labdoo.org, home base for the Labdoo project, a 501(c)(3) organization. The project’s About page explains its goals:
“A laptop is a door to education, providing children free access to open source education tools and electronic books through the Internet.
“In the richer countries, every year more than a hundred million laptops are replaced by new ones. This number continues to increase, yet most of the children in the poor regions of the world still lack access to education.
“The goal of Labdoo is to use grassroots, decentralized, social networking tools to efficiently bring excess laptops to the children in the developing world without wasting additional Earth resources.
“Join Labdoo and use the social network tools to bring a laptop to a child!”
A worthy cause, to be sure. Though the project won’t be officially launched until early next year, its Web site is up and running. The organization encourages visitors to use its tools to build their own “mini-missions and hubs.” Doing so, it emphasizes, will help further the development of their platform.
Neofonie began as an offshoot of the Technical University of Berlin. They make it a point to meet, and to innovate beyond, market demands. The company produces enterprise search as well as portal and vertical search products for both Web solutions and mobile apps.
Cynthia Murrell, August 10, 2012
Sponsored by ArnoldIT.com, developer of Augmentext
Will New CEOs Knock Out Search Revenue Pains?
August 8, 2012
Two search vendors have recently announced shuffling in their top management positions. The first vendor – Perfect Search. The enterprise search technology vendor replaced its President and CEO of five years last May 2012. George Watanabe, co-founder and VP of Business Development and Investor Relations filled in the empty seat.
The second vendor – MarkLogic. Also in May 2012, “Gary Bloom Joins MarkLogic as Chief Executive Officer”:
“MarkLogic Corporation, the company powering mission-critical Big Data Applications around the world, today announced that Gary Bloom… has been named president and chief executive officer.
Gary brings an exceptional background that includes more than two decades of successful leadership in enterprise software. He was the CEO and president at eMeter, which provides smart grid management software for electric, gas, and water utilities… Prior to that, Gary was a consultant of TPG, a leading global private investment firm.”
Both Watanabe and Bloom have the potential to further pave the way for success of their respective companies, given their impressive technical background in enterprise applications. But both companies have joined the bandwagon and just lately added Big Data to their focus. We’re waiting to see if the move to change executives will tip the enterprise search and Big Data scales in their favor.
Lauren Llamanzares, August XX, 2012
Sponsored by ArnoldIT.com, developer of Augmentext
Track the Output of SharePoint Fast Search Crawl Logs
August 7, 2012
Do you need to pull SharePoint Fast Search crawl logs? We do. We read with interest an item on Microsoft’s TechNet Web site. “Get SharePoint Search Crawl Logs” provides an almost ready-to-run script which will accept a search service name and display the associated crawl logs. If there is a crawl log with an error, the script flags that instance. To script can be edited so that it returns different information from the crawly logs. In order to make this tweak, the $crawlLogFilters can be edited.
SharePoint Fast usually does an excellent job of processing content. However, some documents can be malformed or an unexpected network issue can arise. As a result, certain content can be skipped or ignored. A visual inspection of crawl logs is not practical when SharePoint is processing large volumes of content.
If you want to view the crawl logs, TechNet provides a wealth of information. A good place to begin your investigation is in the TechNet Library. If you want to expOrt the SharePoint 2010 search crawl logs, you will find a useful Powershell script in Dave Mc’s Blog in the article “Export the SharePoint 2010 Search Crawl Log.” MSDN also provides information about exporting SharePoint 2010 search crawl logs. To access this information, navigate to the SharePoint Escalation Team’s blog.
Search Technologies’ team of experienced engineers can provide automation tools which eliminate the need to search for solutions to common problems. To learn more about our SharePoint and FFast Search implementation services, navigate to http://www.searchtechnologies.com/microsoft-search.html or contact us at info@searchtechnologies.com.
Iain Fletcher, August 7, 2012
Sponsored by Augmentext
Research and Development Innovation: A New Study from a Search Vendor
August 3, 2012
I received message from LinkedIn about a news item called “What Are the Keys to Innovation in R&D?” I followed the links and learned that the “study” was sponsored by Coveo, a search vendor based in Canada. You can access similar information about the study by navigating to the blog post “New Study: The Keys to Innovation for R&D Organizations – Their Own, Unused Knowledge.” (You will also want to reference the news release about the study as well. It is on the Coveo News and Events page.

Engineers need access to the drawings and those data behind the component or subsystem manufactured by their employer. Text based search systems cannot handle this type of specialized data without some additional work or the use of third party systems. A happy quack to PRLog: http://www.prlog.org/10416296-mechanical-design-drawing-services.jpg
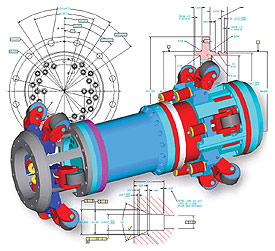{kind=link}
The main of the study, as I interpret it, is marketing Coveo as a tool to facilitate knowledge management. Even though I write a monthly column for the print and online publication KMWorld, I do not have a definition of knowledge management with which I am comfortable. The years I spent at Booz, Allen & Hamilton taught me that management is darned tough to define. Management as a practice is even more difficult to do well. Managing research and development is one of the more difficult tasks a CEO must handle. Not even Google has an answer. Google is now buying companies to have a future, not inventing its future with existing staff.
The unhappy state of many search and content processing companies is evidence that those with technological expertise may not be able to generate consistent and growing revenues. Innovation in search has become a matter of jazzing up interfaces and turning up the marketing volume. The $10 billion paid for Autonomy, the top dog in the search and content processing space, triggered grousing by Hewlett Packard’s top executives. Disappointing revenues may have contributed to the departure of some high profile Autonomy Corporation executives. Not even the HP way can make traditional search technology pay off as expected, hoped, and needed. Search vendors are having a tough time growing fast enough to stay ahead of spiking technical and support costs.
When I studied for a year at the Jesuit-run Duquesne University, I encountered Dr. Frances J. Chivers. The venerable PhD was an expert in epistemology with a deep appreciation for the lively St. Augustine and the comedian Johann Gottlieb Fichte. I was indexing medieval Latin sermons. I had to take “required” courses in “knowledge.” In the mid 1960s, there were not too many computer science departments in the text indexing game, so I assume that Duquesne’s administrators believed that sticking me in the epistemology track would improve the performance of my mainframe indexing software. Well, let me tell you: Knowledge is a tough nut to crack.
Now you can appreciate my consternation when the two words are juxtaposed and used by search vendors to sell indexing. Dr. Chivers did not have a clue about what I was doing and why. I tried to avoid getting involved in discussions that referenced existentialism, hermeneutics, and related subjects. Hey, I liked the indexing thing and the grant money. To this day, I avoid talking about knowledge.
Selected Findings
Back to the study. Coveo reports:
We recently polled R&D teams about how they use and share innovation across offices and departments, and the challenges they face in doing so. Because R&D is a primary creator and consumer of knowledge, these organizations should be a model for how to utilize and share it. However, as we’ve seen in the demand for our intelligent indexing technology, and as revealed in the study, we found that R&D teams are more apt to duplicate work, lose knowledge and operate in soloed, “tribal” environments where information isn’t shared and experts can’t be found. This creates a huge opportunity for those who get it right—to out-innovate and out-perform their competition.
The question I raised to myself was, “How were the responses from Twitter verified as coming from qualified respondents?” And, “How many engineers with professional licenses versus individuals who like Yahoo’s former president just arbitrarily awarded themselves a particular certification were in the study?” Also, “What statistical tests were applied to the results to validate the the data met textbook-recommended margins of error?”
I may have the answers to these questions in the source documents. I have written about “number shaping” at some of the firms with which I have worked, and I have addressed the issue more directly in my opt in, personal news service Honk. (Honk, a free weekly newsletter, is a no-holds-barred look at one hot topic in search and content processing. Those with a propensity to high blood pressure should not subscribe.)
-

- Subscribe to Beyond Search
Feature archive
News archive

-